The Basics of Caches
- 注意cache分两种,Icache 和 Dcache
时间局部性(Temporal Locality)
定义:时间局部性指的是程序在某一时间点访问的数据,在未来一段时间内可能会再次被访问。
- 体现方式
如果程序在某一时刻访问了某个数据,它很可能会在不久的将来再次访问该数据。CPU缓存(如L1缓存)和操作系统的页表会利用时间局部性,在数据再次被访问时可以从缓存或内存中快速获取。
举例:
假设有一个程序循环访问数组并进行某些计算
#define SIZE 1024
int array[SIZE];
void process() {
for (int i = 0; i < SIZE; i++) {
array[i] += 1; // 多次访问array[i]
}
}
int main() {
process();
return 0;
}
- 分析
- 程序在处理过程中,访问的数组元素是顺序的,每次都会访问 array[i]。
- 时间局部性体现在:每次访问后,array[i]的值可能会在同一个计算周期内被再次修改或读取。例如,当进行某些循环时,array[i] 可能在之后的计算中再次被访问。
- 通过缓存设计(如LRU缓存策略),这部分数据会被保留在缓存中,提高程序的访问速度。
空间局部性(Spatial Locality)
定义:空间局部性指的是程序访问的数据是相邻的或靠近的。换句话说,当程序访问某个内存位置时,它很可能接下来会访问该位置附近的内存数据。
- 体现方式
顺序访问是空间局部性的一个典型例子,程序按顺序访问数组、结构体、矩阵等数据时,会利用缓存块(cache block)预加载相邻数据,提高命中率。
在现代缓存中,一块缓存通常会存储相邻的多个内存单元。因此,如果程序访问了某个数据,它可能会将邻近的数据加载到缓存中以供之后使用。
举例:
假设有一个程序按行遍历二维数组:
#define N 128
int matrix[N][N];
void process() {
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
matrix[i][j] += 1; // 按行访问
}
}
}
int main() {
process();
return 0;
}
-
分析
- 在这个例子中,程序按行顺序访问二维数组 matrix[i][j],即相邻的元素会被顺序访问。
- 由于大多数编程语言(如C语言)使用行优先存储,即矩阵的元素是按行存储在内存中的,所以访问 matrix[i][j] 后,相邻的元素(matrix[i][j+1])会被连续访问。
- 空间局部性得到了很好的体现,程序会很高效地利用缓存,因为一次加载缓存块时会带入相邻的数据,减少缓存miss。
局部性差:跳跃访问/链表访问
当程序访问数据时并非顺序地、线性地访问,而是跳跃性地访问某些数据时,空间局部性可能会下降。此时,缓存设计的优化会面临挑战。
举例:
假设有一个程序按固定步长访问数组:
#define SIZE 1024
int array[SIZE];
void process() {
for (int i = 0; i < SIZE; i += 64) {
array[i] += 1; // 跳跃性访问
}
}
int main() {
process();
return 0;
}
分析:
- 这个程序每次访问数组 array[i] 时跳过 63 个元素,因此访问模式是跳跃性的。
- 空间局部性较差,因为访问的数组元素分布在内存中较远的地方,而内存加载时会一次加载一整个缓存块(如64字节),但大部分数据是没用的,会浪费缓存资源。
- 如果此时缓存块过大(如128B或256B),那么可能会加载大量未使用的数据,导致缓存miss率上升。
空间局部性不足会导致大块数据加载后,只有部分数据会被有效利用,因此缓存块的设计需要小一些,才能减少缓存污染。
时间和空间局部性的结合
有些程序的访问模式同时体现了时间局部性和空间局部性。例如,矩阵乘法通常既有空间局部性(按行、按列访问矩阵的元素),也有时间局部性(某个元素可能会在计算过程中多次使用)。
举例:
#define N 128
int A[N][N], B[N][N], C[N][N];
void process() {
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
C[i][j] = 0;
for (int k = 0; k < N; k++) {
C[i][j] += A[i][k] * B[k][j]; // 矩阵乘法
}
}
}
}
int main() {
process();
return 0;
}
分析:
- 这个程序进行矩阵乘法,按行和列访问矩阵 A[i][k] 和 B[k][j]。
- 空间局部性:矩阵是行优先存储,因此在访问 A[i][k] 和 B[k][j] 时,内存访问模式是相邻元素的访问,可以很好地利用缓存。
- 时间局部性:C[i][j] 在每一轮内都会被多次访问,因此,缓存中可能会保留 C[i][j] 以供多次使用。
总结
- 时间局部性体现了程序倾向于重复访问相同的数据,这样缓存可以有效地保留最近访问的数据,减少miss。
- 空间局部性体现了程序倾向于访问相邻的内存位置,较大的缓存块可以加载更多相邻的数据,提高缓存命中率。
如何设计cache
通过理解这些基本的访问模式和局部性原理,我们可以优化缓存设计,提高程序的执行效率,尤其是在处理大规模数据时,这里特别需要注意的是Icache和Dcache的区别,两者存在区别也就意味着会在设计上存在不同的考量。
Icache和Dcache的区别
- Icache(指令缓存):存储CPU将要执行的指令,通常通过顺序访问,程序的指令流一般是连续的,虽然会有分支跳转,但指令的访问模式一般是线性的。
- Dcache(数据缓存):存储程序中用到的数据,访问模式更为复杂,可能会有顺序访问、随机访问、跳跃访问等,因此其设计更需要考虑多种数据访问模式。
[!NOTE] 非常重要的区别.
Dcache 的访问模式
Dcache的设计需要考虑更多的因素,因为它会受到程序数据访问模式的直接影响。访问模式的设计正是Dcache优化的核心之一。常见的数据访问模式有:
- 顺序访问(例如线性遍历数组):这种模式下,访问是连续的,相邻的数据会被连续访问,因此Dcache的设计可以利用空间局部性来提高命中率。
- 跳跃访问(例如每隔几个元素访问):在这种模式下,缓存块的大小不应过大,因为大块数据中会有很多不被访问的数据,浪费缓存资源。
- 二维矩阵的访问(行优先和列优先):由于大部分编程语言(如C)采用行优先存储,按行访问会有更好的空间局部性,而按列访问则可能导致较差的缓存命中率。
- 链表访问:链表是指针跳跃式访问的,Dcache需要特别优化以应对这种访问模式,通常会用较小的缓存块,避免一次加载不需要的内存。
Dcache 设计的综合考虑
设计 Dcache 时,需要综合以下几个因素来平衡不同的需求,尤其是访问模式的影响:
块大小(Cache Block Size)
- 小块缓存:适合数据访问非常分散(如跳跃访问)或结构不连续的数据(如链表)。小块缓存可以减少无效数据的加载,提高缓存的有效利用率。
-
大块缓存:适合顺序访问模式(如顺序遍历数组)。大块缓存有助于提升空间局部性,减少miss。通常大块缓存会在读取大量连续数据时产生较大的收益。
- 设计上的折衷:在一般情况下,Dcache的块大小通常选为 32B - 128B,这种大小能够在不同类型的程序中都提供较好的缓存命中率。
关联度(Associativity)
缓存的关联度(Associativity)指的是缓存中每个块可以存放在哪些位置(即,块可以映射到哪个组)。缓存的关联度越高,查找缓存块所需的时间越长,但能够减少缓存冲突(cache conflict),避免数据被过早地替换掉。
- 低关联度(如2-way):通常具有较快的查找速度,但容易出现缓存冲突。
- 高关联度(如8-way):减少了冲突的可能性,但查找速度较慢,需要更多的硬件资源。
- 设计考虑:Dcache的设计会根据访问模式来调节关联度。如果程序有较多的随机访问,可能会选择较高的关联度,以减少冲突。如果是顺序访问,低关联度会更有效。
缓存替换策略(Replacement Policy)
- LRU(Least Recently Used):适用于顺序访问或者局部性较好的访问模式。LRU会保留最近使用的数据,淘汰较少使用的数据。
- FIFO(First In First Out):简单的替换策略,适合访问模式较为简单或不太有局部性的情况。
- 随机替换:适用于没有明显访问模式的程序,能够避免某些情况下的局部性问题。
- 设计考虑:对于Dcache来说,最常见的替换策略是LRU,因为大多数程序有空间局部性和时间局部性,LRU能较好地捕捉这些特性。但在面对链表这种不规则访问模式时,可能会采用随机替换。
数据预取(Prefetching)
- 顺序预取:当系统检测到顺序访问的模式时,Dcache可以预取下一个或多个缓存块,从而减少缓存miss。例如,遍历数组时可以提前加载接下来的几个元素。
- 非顺序预取:对于跳跃访问或随机访问的模式,预取可能会更加复杂,需要根据程序的访问历史来预测接下来的访问地址。
- 设计考虑:在设计Dcache时,如果程序访问数据时有明确的顺序性,可以开启顺序预取;但对于不规则访问模式(如链表访问),预取可能导致缓存污染,增加缓存miss的概率。
多级缓存架构(L1, L2, L3)
在大多数现代处理器中,缓存通常分为多级缓存架构(L1、L2、L3):
- L1缓存:通常分为Icache和Dcache,容量较小(通常为32KB - 128KB),优化为低延迟访问。
- L2缓存:比L1缓存大(通常为256KB - 2MB),主要是对L1缓存的补充,具有较高的命中率,能够支持较大的数据块。
- L3缓存:通常共享的缓存,容量较大(几MB到几十MB),适合处理多核处理器之间的缓存共享和大规模数据访问。
- 设计考虑:
- L1 Dcache在设计时需要尽量优化低延迟,以支持快速的单个数据访问。
- L2 Dcache则更多地考虑容量与速度的平衡,用于存储较大范围的数据。
- L3缓存则负责处理跨核共享的数据,虽然延迟较高,但能提供更大的容量和较好的共享性能。
总结:Dcache设计的综合考虑
Dcache的设计需要综合考虑多种因素,尤其是程序的访问模式,主要包括:
- 访问模式的多样性:例如顺序访问、跳跃访问、二维矩阵访问等,每种模式都需要不同的缓存块大小、关联度、替换策略等。
- 缓存大小和层次结构:根据多级缓存设计,L1缓存较小,优化访问速度;L2和L3缓存较大,优化容量和共享访问。
- 替换策略和预取策略:LRU适合空间局部性强的程序,随机替换适合随机访问程序,预取策略可以在适当时机降低miss率。
- 功耗与成本:缓存越大、关联度越高、预取机制越复杂,都会增加功耗、芯片面积和成本,因此需要平衡。
总体来说,Dcache设计是非常复杂的,它需要根据程序的具体访问模式来优化缓存大小、缓存结构、替换策略等
终极问题
在书中Computer Organization and Design: The Hardware/ Software Interface, Fifth Edition, Page 391有下面一段总结
Larger blocks exploit spatial locality to lower miss rates. As Figure 5.11 shows, increasing the block size usually decreases the miss rate. Th e miss rate may go up eventually if the block size becomes a signifi cant fraction of the cache size, because the number of blocks that can be held in the cache will become small, and there will be a great deal of competition for those blocks. As a result, a block will be bumped out of the cache before many of its words are accessed. Stated alternatively, spatial locality among the words in a block decreases with a very large block; consequently, the benefi ts in the miss rate become smaller.
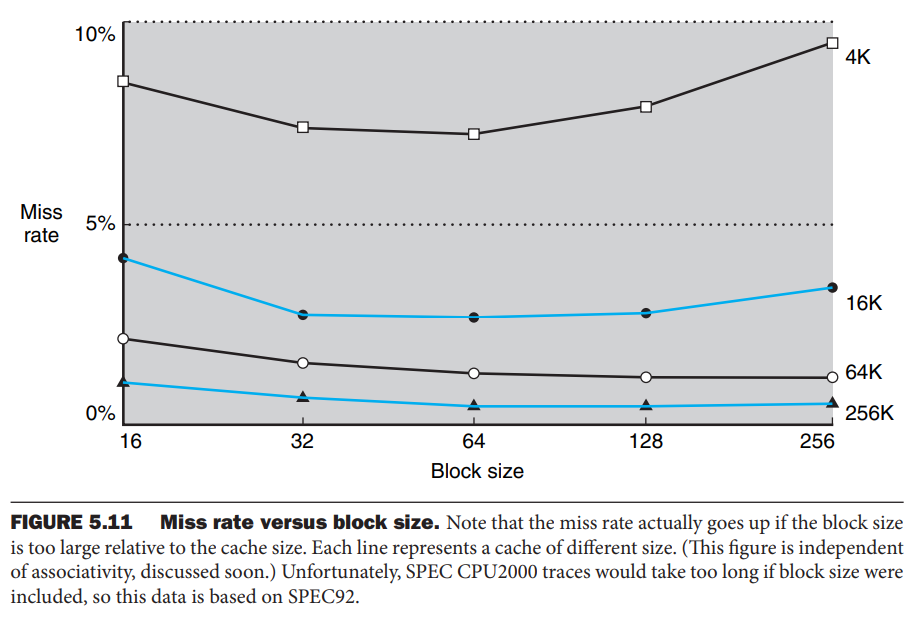
为什么块变得“过大”时,空间局部性会降低?
当块大小较小时,加载进缓存的内容往往都是程序即将访问的地址范围,因此可以充分利用空间局部性。但如果块大小过大,会出现以下问题:
- 程序的访问模式决定了真正有效的数据量:
- 典型的程序访问模式往往是局部的,例如数组操作时,通常访问的是相邻的少量元素,而不是整个大块的数据。
- 如果块过大,虽然会加载更多数据,但这些数据可能在短时间内不会被访问,导致实际利用率下降。
- Cache 资源有限,块变大导致块数减少:
- 例如,假设缓存总大小是 64 KB,如果块大小是 16 B,则可以存储 4096 个块;
- 但如果块大小增加到 4 KB,则只能存储 16 个块;
- 这样,同样大小的缓存只能存放更少的块,导致块之间竞争加剧,缓存替换频繁,使得数据还未被充分利用就被淘汰。
- 空间局部性的影响范围有限:
- 真实程序的空间局部性通常在较小的范围内是有效的,例如几条指令或少量数据单元。
- 如果块过大,则块内部的数据彼此之间的访问可能性降低,使得大块数据的有效性减弱。
结论
当块过大时,虽然仍然能利用一定的空间局部性,但由于:
- 访问模式导致有效数据减少,
- 缓存块数减少导致替换频繁,
- 过大的数据范围导致空间局部性效果下降,
最终,块的增大会减少缓存的有效性,使得空间局部性对缓存命中率的提升作用变小,甚至可能导致更高的缓存缺失率(Miss Rate)。
为什么不将L1做成10M大小的空间?
访问速度 vs. 缓存大小
L1缓存的设计目标是极低的访问延迟,通常只有1-4个时钟周期(cycle)。如果L1缓存变得过大,其访问时间会变长,导致CPU性能下降。
原因:
- 查找时间增加:
- 典型的L1缓存使用全相联(fully associative)或组相联(set associative)策略,随着缓存变大,查找(lookup)所需的时间也会增加,增加了CPU的访存延迟。
- 物理限制:
- L1缓存通常位于CPU核心的内部(on-die),受限于芯片面积,如果L1做得过大,会影响其他关键组件(如ALU、寄存器、执行单元等)的布局。
在高性能处理器中,L1缓存通常保持较小(例如32KB),确保在极短的时间内完成访问,从而提升CPU的指令执行效率。
能耗和功耗
L1缓存属于SRAM(静态随机存取存储器),相比于DRAM(动态随机存取存储器,如主存)具有高速度、高功耗的特点。
如果L1缓存从32KB增加到1MB或10MB,会导致:
- 更高的功耗:SRAM的功耗随着容量增大呈线性增长。
- 更多的热量:高功耗会带来更大的散热挑战,影响芯片稳定性和散热设计。
- 更长的启用时间:大缓存需要更多的控制电路,增加功耗管理的复杂度。
在移动设备(如智能手机)和服务器中,功耗是关键因素,因此L1缓存的大小需要在性能和功耗之间取得平衡。
命中率的收益递减
L1缓存的主要作用是缓存最常用的数据,提高缓存命中率(hit rate),减少对L2/L3缓存或主存的访问。但当L1缓存变大时,命中率的提升会逐渐减小。
假设:
- 32KB L1缓存的命中率为 95%
- 64KB L1缓存的命中率可能提升到 97%
- 128KB L1缓存的命中率可能提升到 98%
- 1MB L1缓存的命中率可能只有 99%
但问题是,从 95% → 99% 的提升,代价是缓存延迟、功耗和芯片面积的巨大增加。而现代CPU已经设计了多级缓存(L1、L2、L3),可以用更大的L2/L3缓存来提升整体性能,而不必让L1过大。
多级缓存架构的优化
现代CPU通常采用L1 + L2 + L3的缓存层次结构,来平衡速度、容量和功耗:
- L1缓存(32KB - 64KB):超高速,低延迟(1-4 cycle),用于存放最常访问的数据和指令。
- L2缓存(256KB - 2MB):较快,适中延迟(10-20 cycle),用于存放L1淘汰但仍然常用的数据。
- L3缓存(几MB - 数十MB):更大,但延迟较高(40-60 cycle),用于不同核心之间共享数据。
如果L1缓存增加到1MB或10MB,就会与L2/L3缓存的作用重叠,打破这种优化结构,使得整体性能和功耗不成比例地增加。
现代CPU的设计取舍
不同架构的CPU在L1缓存大小上有不同的优化策略:
- x86架构(Intel/AMD):
- 典型L1数据缓存为 32KB,L1指令缓存也是 32KB,以极低延迟为优化目标。
- L2缓存一般 512KB - 2MB,L3缓存 8MB - 64MB。
- ARM架构(移动端、嵌入式):
- 典型L1缓存较小(16KB - 64KB),因为功耗敏感。
- 依靠L2/L3缓存和高效预取策略来优化整体性能。
这些设计都是基于缓存大小 vs. 访问延迟 vs. 功耗的权衡。
结论
L1缓存之所以不设计成1MB或10MB,主要是基于以下几个因素:
- 访问延迟:L1缓存需要尽可能快,不能因为变大而影响CPU性能。
- 功耗与能耗:SRAM功耗高,过大的L1缓存会增加能耗,影响散热和续航(特别是在移动设备中)。
- 收益递减:L1缓存变大后,命中率的提升幅度越来越小,得不偿失。
- 多级缓存架构:现代CPU使用L1+L2+L3分层优化,L1缓存不需要无限增大。
因此,32KB - 64KB 的 L1 缓存已经是当前主流处理器架构下最合理的选择,它提供了极低延迟、较高命中率,同时不会过度增加功耗和芯片面积。
从存储的层次结构来看, L1 L2 L3 memory disk每两层之间都体现了局部性的原理,以及通过局部性原理来提速(既满足快又做到了大)。
